-
TIL.36 selenium을 이용한 이미지 크롤링 자동화TIL 2020. 11. 13. 19:13728x90반응형
step . 1 : 파이썬 가상 환경 세팅하기 ## 출처 : 유투브 조코딩님
venv 가상 환경을 이용해 파이썬내에서 가상 환경을 세팅해보자
파이썬 버전이나 라이브러리가 각각 만들고자하는 프로젝트별로 호환등의 이유로 다를 수 있는데
한 컴퓨터 내에서 python 3.8 / python 3.5/ python 2.7 등을 선택해서 사용해야하는 환경을 만들어 줘야하는데
이를 가상 환경이라 하며 venv 가상 환경을 사용하였다.
이를 ven 가상 환경을 만들어주는 방법으로 구현해보자
# 터미널 창에서 아래 venv 명령을 실행하여 만들어 진다.
python3 -m venv /path/to/new/virtual/environment # 여기서 내 컴퓨터에는 python3 -> python venv 뒤의 경로는 selenium(이름 자유)로 가상 환경을 만들 수 있다.나는 아래와 같이 작성하여 셀레니움을 생성하였다.
python3 -m venv selenium # mun 이라는 폴더에 selenium이란 이름의 가상환경이 만들어진다. # 여기서 이름은 아무거나 입력해도 상관없다
위와 같이 mun 폴더안에 selenium 이라는 가상환경이 생성된다.
여기서 cmd 화면에서 cd selenium\Scripts 를 입력하여 폴더로 들어가주고
activate 명령어를 실행하여 가상 환경에 들어가주면
(selenium) C:\Users\user\Desktop\mun\selenium\Scripts> 앞의
(selenium)처럼 우리가 들어와있는 창은
가상환경에 들어왔다는걸 알려주는 표시이다.

이 표시가 붙은 상태로 파이썬 코드를 실행하거나 패키지를 설치해주면
이 selenium 이라고 하는 가상환경에서 실행되고 설치되는거기 때문에
다른 프로젝트와 독립적인 공간에서 패키지를 설치하고 사용할 수 있다.
step. 2 Selenium 설치 및 브라우저 세팅
cmd에서 pip install selenium 명령어 실행하여 설치해주자
설치 완료 후
selenium으로 활용할 웹 브라우저를 세팅해야한다.
크롬을 사용하도록 하겠다.
크롬을 사용하기 위해 크롬에서 크롬 드라이버(chromedriver)를 내 크롬 버전에 맞는 드라이버를 설치해주자

다운받은 크롬드라이버를 selenium 파일 안쪽으로 옮겨주자
모든 파일을 selenium 파일안에 옮겨줬다면 해당 파일 안에 goolgle.py를 만들어 본격적으로 이미지 크롤링을 위한 코드를 작성해보자 (이때 크롬드라이버와 google.py는 같은 경로에 있어야한다.)

step. 3 selenium 예제 코드를 이용해 순차적으로 코드를 적어나가보자
구글링을 통해 selenium 예시 코드를 가져다 사용하도록 하자. (python selenium example)
from selenium import webdriver from selenium.webdriver.common.keys import Keys driver = webdriver.Firefox() driver.get("http://www.python.org") assert "Python" in driver.title elem = driver.find_element_by_name("q") elem.clear() elem.send_keys("pycon") elem.send_keys(Keys.RETURN) assert "No results found." not in driver.page_source driver.close()예시코드를 붙혀넣기를 하면, vs코드에 빨간 줄이 생기는데
이 이유는 selenium을 가상환경에 설치했는데 vs코드는 가상환경이 아닌 그냥 컴퓨터의 설치된 파일로 인식하고 있어 발생하는 것으로
셀레니움이 설치 되지 않았다고 판단하고 있기 때문이다.
이를 해결하기 위해 왼쪽 하단을 클릭하여 우리의 가상환경인 selenium을 선택해주면 된다.
웹드라이버로 사용하느 chrome()으로 변경과 함께
홈페이지 주소를 정해준다.
driver = webdriver.Chrome() # 크롬으로 변경 driver.get("https://www.google.co.kr/imghp?hl=ko&tab=ri&ogbl") # 구글 이미지 홈페이지 주소터미널 창에서 아래와 같이
python google.py 명령어로 실행하면 구글 이미지 홈페이지가 정상적으로 작동되는걸 알 수 있다.

step. 4 코드 구현하기
위에 예시에서는 1 2 번째 줄로만 출력되는 것을 확인하였으며
직접 어떠한 기능을 쓸때는 어떠한 코드가 필요한지 구글링을 하는 방법으로 하나하나
단계적으로 접근해보자.
이미지를 다운로드하는 방법은 우선 간단하게 적어보자면
구글 홈페이지 접속 -> 입력창에 찾고자하는 키워드 (값) 입력 ->
나오는 이미지 들을 클릭 -> 크게 다시 나오는 이미지에서 오른쪽마우스로 다른이름으로 저장
방법으로 이루어지며, 이를 하나하나 코드로 구현이 가능하다.
구글 홈페이지 접속하는 방법은 아래 1, 2 번째 코드로 완성
from selenium import webdriver from selenium.webdriver.common.keys import Keys driver = webdriver.Chrome() ## 크롬 브라우저를 위한 크롬 웹드라이버로 설정 driver.get("https://www.google.co.kr/imghp?hl=ko&tab=ri&ogbl") # 크롤링을 시작할 구글 이미지 홈페이지 주소입력창에 찾고자하는 키워드(값) 입력
찾고자하는 값은 "조코딩"으로 검색창에 조코딩을 입력 후 엔터(검색)을 실행하면 된다.
구글의 개발자도구로 입력창을 확인하여 이름은 무엇인지, 클래스 명은 무엇인지 등 정보를 확인할 수 있다.
그럼 검색창을 찾고, 우리가 원하느 검색어를 입력하는 단계를 진행해보자
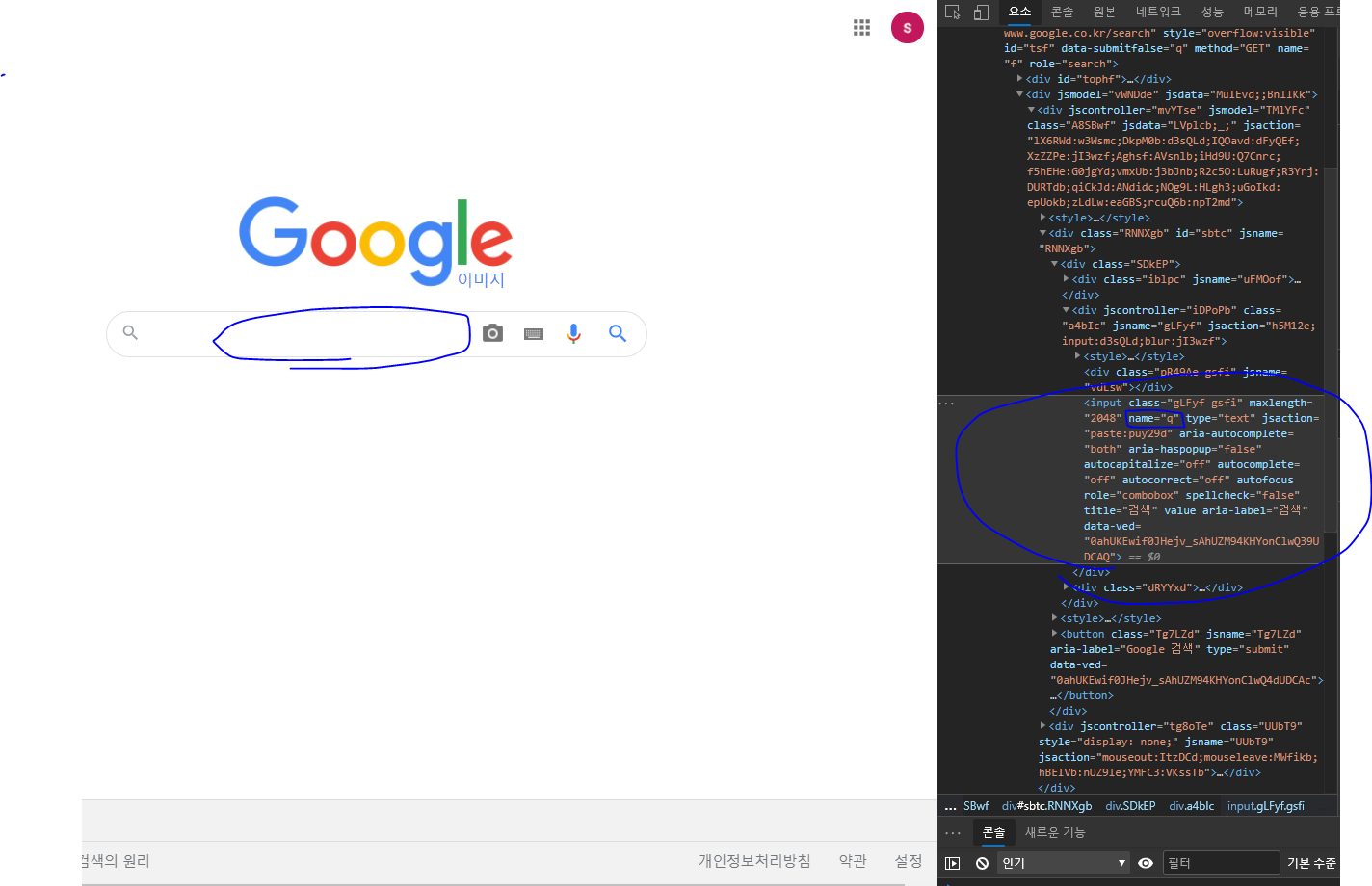
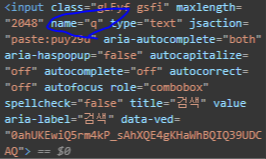
from selenium import webdriver from selenium.webdriver.common.keys import Keys driver = webdriver.Chrome() driver.get("https://www.google.co.kr/imghp?hl=ko&tab=ri&ogbl") elem = driver.find_element_by_name("q") # 특정 요소 찾는 코드우리가 원하는 특정 요소를 찾는 코드는
find_element_by_name("q")을 이용해 검색창 의 name = q라는 점을 이용해 검색창을 찾는다.
find은 다양한 방법으로 찾을 수 있는데, element는 요소 하나, elements는 다수의 요소 한번에 선택해서 담을때사용한다.

찾은 검색창에
send_keys('값') 을 이용해 검색창에 조코딩을 입력한 상태까지 코드를 작성해보자.
from selenium import webdriver from selenium.webdriver.common.keys import Keys driver = webdriver.Chrome() driver.get("https://www.google.co.kr/imghp?hl=ko&tab=ri&ogbl") elem = driver.find_element_by_name("q") # 기술자도구에서 검색어의 이름 d를 이용해 elem이라는 변수 칸을 찾는다 elem.send_keys("조코딩") # send_keys를 이용해서 우리가 원하느 값인 (조코딩)을 넣어준다.
실행만 시켰을뿐 위의 이미지까지는 모두 자동화로 이루어졌다.
step. 5 코드 구현하기_2
조코딩 까지 입력한 후 검색 버튼을 눌러 이미지를 모두 찾아보자
send_keys(keys.RETURN) 코드는 엔터를 치는것을 의미한다.
from selenium import webdriver from selenium.webdriver.common.keys import Keys driver = webdriver.Chrome() driver.get("https://www.google.co.kr/imghp?hl=ko&tab=ri&ogbl") elem = driver.find_element_by_name("q") elem.send_keys("조코딩") # send_keys를 이용해서 우리가 원하느 값인 (조코딩)을 넣어준다. elem.send_keys(Keys.RETURN) # 검색어에 조코딩 입력후 엔터(검색실행)
엔터를 치는것을 구현하였다면 각 이미지를 클릭해야한다.
다시 개발자 도구를 이용해 작은 이미지들이 다 선택되도록 만들어 보자


.find_elements_by_css_selector를 이용해 여러개의 이미지를 선택
css_selector를 이용해 클래스 이름 rg_i Q4Luwd 를 가지고 있는 모든 것을 선택해준다.
(보통 유사한 요소들은 클래스명이 동일하다)
선택을 했다면 클릭을 해줘야하는데
driver.find_elements_by_css_selector(".rg_i.Q4LuWd")[0].click().click() 으로 클릭을 구현하고, elements 들로 여러개가 선택이 되어있는데
그 중 가장 첫번째를 클릭해달라는 [0]을 붙혀줌으로써 아래와 같은 화면까지 자동화를 구현 할 수 있다.

여기까지 하였다면 큰 이미지 화면을 저장해주면 되는데


.find_element_by_css_selector(".n3VNCb") 를 이용해 큰 이미지를 선택해주고
이미지의 src 즉, 주소부분을 가져와서 다운로드 해주는 코드를 만들어보자
구글링을 이용해 import urllib.request 를 이용해하여 이미지를 저장하는 코드를 작성하였다
(python image download by url
여기서 추가로 모든 이미지 로드하고 선택하는데 브라우저에게 어느정도 시간이 필요하다고 한다.
따라서 time 모듈을 사용해 어느정도 시간을 주고나서 코드를 실행시키자.
import time import urllib.request driver.find_elements_by_css_selector(".rg_i.Q4LuWd")[0].click() # 첫 번째 큰이미지 선택 + 클릭 time.sleep(3) 이미지 로드 시간 3초 부여 imgUrl = driver.find_element_by_css_selector(".n3VNCb").get_attribute("src") # 이미지 선택 후 src 주소 가져오는 코드 urllib.request.urlretrieve(imgUrl, "00000001.jpg") # urllib.request 모듈을 이용해 이미지를 저장하는 코드
이처럼 0001.jpg 이미지를 자동으로 다운로드하였다
step. 5 코드 구현하기_3
당연히 이미지 하나가 아닌 모든 이미지를 저장할 것이기 때문에 반복문을 이용해 모두 가져오도록 하자.
반복문을 사용하기 위해 이미지를 클릭하는 시점부터의 코드를 반복문으로 만들어주자
driver.find_elements_by_css_selector(".rg_i.Q4LuWd")[0].click() time.sleep(3) imgUrl = driver.find_element_by_css_selector(".n3VNCb").get_attribute("src") urllib.request.urlretrieve(imgUrl, "00000001.jpg")여기서 driver.find_elements_by_css_selector(".rg_i.Q4LuWd")[0].click() 의 결과는 리스트로 나올텐데
이를 이용해 반복문을 작성하여보자
images = driver.find_elements_by_css_selector(".rg_i.Q4LuWd") count = 1 #저장되는 파일명의 중복을 피하기 위해1 for image in images: image.click() # 각 이미지를 클릭 time.sleep(3) # 시간 부여 imgUrl = driver.find_element_by_css_selector(".n3VNCb").get_attribute("src") urllib.request.urlretrieve(imgUrl, str(count)+".jpg") # #저장되는 파일명의 중복을 피하기 위해1 count += 1 #저장되는 파일명의 중복을 피하기 위해1여기까지 작성하여 아래 코드로 동작해보면 3초마다 이미지 1장을 저장하는 것을 알 수 있다.
from selenium import webdriver from selenium.webdriver.common.keys import Keys import time import urllib.request driver = webdriver.Chrome() driver.get("https://www.google.co.kr/imghp?hl=ko&tab=wi&authuser=0&ogbl") elem = driver.find_element_by_name("q") elem.send_keys("조코딩") elem.send_keys(Keys.RETURN) images = driver.find_elements_by_css_selector(".rg_i.Q4LuWd") count = 1 for image in images: image.click() time.sleep(3) imgUrl = driver.find_element_by_css_selector(".n3VNCb").get_attribute("src") urllib.request.urlretrieve(imgUrl, str(count)+".jpg") count += 1
여기서 왜 사진은 20장 까지만 저장이 될까??
처음 검색하였을때 나오는 이미지는 20장이 전부이기 때문이다.
(강의에서는 50장이 나왔었다)
step. 6 코드 구현하기_4
여기서 왜 사진은 20장 까지만 저장이 될까?? 실제로 이미지수는 훨씬 많다
모든 이미지를 가져오기 위해서는
스크롤을 내릴 수록 이미지는 계속 나오는 점
심지어 결과 더보기를 눌러야지만 이미지가 다시 나온다는 점
결과 더보기를 누른 후 더이상 표시할 컨텐츠가 없습니다 가 나올때까지 스크롤을 내리고 이미지를 가져와야한다.
## 따라서 스크롤을 내리면서 계속 새로운 이미지를 다운로드를 받아와야 한다
(python selenium scroll down) 아래 코드는 자바스크립트 코드라고 한다
last_height = driver.execute_script("return document.body.scrollHeight") ## 여기서 execute_script ==> 자바 스크립트 코드를 실행하는 코드이다.SCROLL_PAUSE_TIME = 0.5 # Get scroll height last_height = driver.execute_script("return document.body.scrollHeight") while True: # Scroll down to bottom driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # Wait to load page time.sleep(SCROLL_PAUSE_TIME) # Calculate new scroll height and compare with last scroll height new_height = driver.execute_script("return document.body.scrollHeight") if new_height == last_height: break last_height = new_height여기서 한번 생각해 볼것이 이미지를 저장하고 스크롤 내리고 저장하고 내리고 저장하는 법보다느
스크롤을 끝까지 내린 후 모든 이미지를 다 불러온 다음, 한번에 선택하면 된다.
그래서 위의 코드를 아래 ### 자리에 넣어준다.
from selenium import webdriver from selenium.webdriver.common.keys import Keys import time import urllib.request driver = webdriver.Chrome() driver.get("https://www.google.co.kr/imghp?hl=ko&tab=wi&authuser=0&ogbl") elem = driver.find_element_by_name("q") elem.send_keys("조코딩") elem.send_keys(Keys.RETURN) ############################################################ images = driver.find_elements_by_css_selector(".rg_i.Q4LuWd") count = 1 for image in images: image.click() time.sleep(3) imgUrl = driver.find_element_by_css_selector(".n3VNCb").get_attribute("src") urllib.request.urlretrieve(imgUrl, str(count)+".jpg") count += 1
step. 6 코드 구현하기_5
from selenium import webdriver from selenium.webdriver.common.keys import Keys import time import urllib.request driver = webdriver.Chrome() driver.get("https://www.google.co.kr/imghp?hl=ko&tab=wi&authuser=0&ogbl") elem = driver.find_element_by_name("q") elem.send_keys("조코딩") elem.send_keys(Keys.RETURN) SCROLL_PAUSE_TIME = 0.5 # Get scroll height last_height = driver.execute_script("return document.body.scrollHeight") while True: # Scroll down to bottom driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # Wait to load page time.sleep(SCROLL_PAUSE_TIME) # Calculate new scroll height and compare with last scroll height new_height = driver.execute_script("return document.body.scrollHeight") if new_height == last_height: break last_height = new_height images = driver.find_elements_by_css_selector(".rg_i.Q4LuWd") count = 1 for image in images: image.click() time.sleep(3) imgUrl = driver.find_element_by_css_selector(".n3VNCb").get_attribute("src") urllib.request.urlretrieve(imgUrl, str(count)+".jpg") count += 1여기서 스크롤을 끝까지 내리는 자바스크립트 코드를 하나하나 확인해보도록 하자.
먼저 아래 코드는 scrollHeight == 브라우저의 높이를 알 수 있는 코드이다.
브라우저 높이를 자바스크립트로 찾아서 last_height 에 저장해준다.
last_height = driver.execute_script("return document.body.scrollHeight")다음 while 무한 반복문으로 아래 스크립트를 실행하는데
window.scrollTo라는건 document.body.scrollHeight == 브라우저의 높이가 0이 될때까지 내리겠다
즉, 브라우즈 끝까지 스크롤을 내린다는 의미이다.
while True: # Scroll down to bottom driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")브라우저 끝까지 스크롤을 내리고 로딩 될때 동안 time.sleep 으로 어느정도 시간을 부여한다. (0.5초)
스크롤을 내리고 이미지를 로드하는 시간을 위해 0.5 -> 2초 로 늘려주도록 하자.
SCROLL_PAUSE_TIME = 2 last_height = driver.execute_script("return document.body.scrollHeight") while True: driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") time.sleep(SCROLL_PAUSE_TIME)로딩이 끝나고 나면 브라우저의 높이를 다시 구해서 new_hegiht에 저장해준다.
# Calculate new scroll height and compare with last scroll height new_height = driver.execute_script("return document.body.scrollHeight")if 조건문을 사용해 만약에 새로 구한 높이랑 이전 높이가 같다면
내렸을때 더 나오는게 없다는 의미이므로 스크롤을 끝까지 내린것이라 할 수 있다.
그때는 break 로 무한 반복 을 빠져나오면 된다.
while True: # Scroll down to bottom driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # Wait to load page time.sleep(SCROLL_PAUSE_TIME) # Calculate new scroll height and compare with last scroll height new_height = driver.execute_script("return document.body.scrollHeight") if new_height == last_height: break last_height = new_height
step. 7 코드 구현하기_6
구글에서는 스크롤을 끝까지 내리고 결과 더보기를 클릭해야 다시 스크롤을 내릴 수 있기에
결과 더보기를 클릭해주는 경우도 만들어줘야한다.


따라서 스크롤이 끝까지 내려갓을때의 if문안에 결과 더보기 버튼을 클릭하는 코드를 넣어줘야한다.
# 여기서 결과 더보기의 클래스명은 mye4qd이다.
if new_height == last_height: driver.find_element_by_css_selector(".mye4qd").click() last_height = new_height여기까지 코드를 종합해보면 아래와 같다.
from selenium import webdriver from selenium.webdriver.common.keys import Keys import time import urllib.request driver = webdriver.Chrome() driver.get("https://www.google.co.kr/imghp?hl=ko&tab=wi&authuser=0&ogbl") elem = driver.find_element_by_name("q") elem.send_keys("조코딩") elem.send_keys(Keys.RETURN) SCROLL_PAUSE_TIME = 2 # Get scroll height last_height = driver.execute_script("return document.body.scrollHeight") while True: # Scroll down to bottom driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # Wait to load page time.sleep(SCROLL_PAUSE_TIME) # Calculate new scroll height and compare with last scroll height new_height = driver.execute_script("return document.body.scrollHeight") if new_height == last_height: driver.find_element_by_css_selector(".mye4qd").click() last_height = new_height images = driver.find_elements_by_css_selector(".rg_i.Q4LuWd") count = 1 for image in images: image.click() time.sleep(3) imgUrl = driver.find_element_by_css_selector(".n3VNCb").get_attribute("src") urllib.request.urlretrieve(imgUrl, str(count)+".jpg") count += 1위 코드로 정상적으로 우리가 원하는 기능을 모두 구현할 수는 있지만
코드가 종료될경우 error가 하나 발생하게 되는데 이문제는 결과 더보기 버튼을 클릭하고
while 문이 계속되는 상태로 결과 더보기 버튼을 한번 누른 후 다음 스크롤이 내려간 후 에는
결과 더보기 버튼이 존재하지 않기 때문이다.
따라서 python 문법인 try : except: 문법으로 이를 해결 할 수 있다.
if new_height == last_height: try: driver.find_element_by_css_selector(".mye4qd").click() except: break last_height = new_heighttry : 아래 코드를 시도하였다가 실패해서 오류가 나면 except로 오게 되고 반복문을 종료하게 된다
따라서 error가 나지 않고 정상적으로 종류 되는 것을 알 수 있다.
## 이미지 다운로드 중 알수없는 오류가 발생한다고 하는데 이를 안전하게 try, except문으로 pass로 그 이미지는 무시하고 다음 이미지부터 다운로드가 진행되게 작성할 수 있다.
##추가로 큰 이미지를 클릭해야하는 반복문에서 클래스 네임 같은 경우 여러개가 있을 경우가 있어 주의해야한다.
## 내가 생각한데로 다운로드가 되지 않는 경우가 생기기에 조금더 구체적으로 접근해 줄 필요가 있다.
개발자 도구를 통해 내가 찾고자하는 태그로 찾아가 copy > copy selector 또는 copy Xpath 또는 copy full Xpath
로 구체화해줄 필요가 있다.
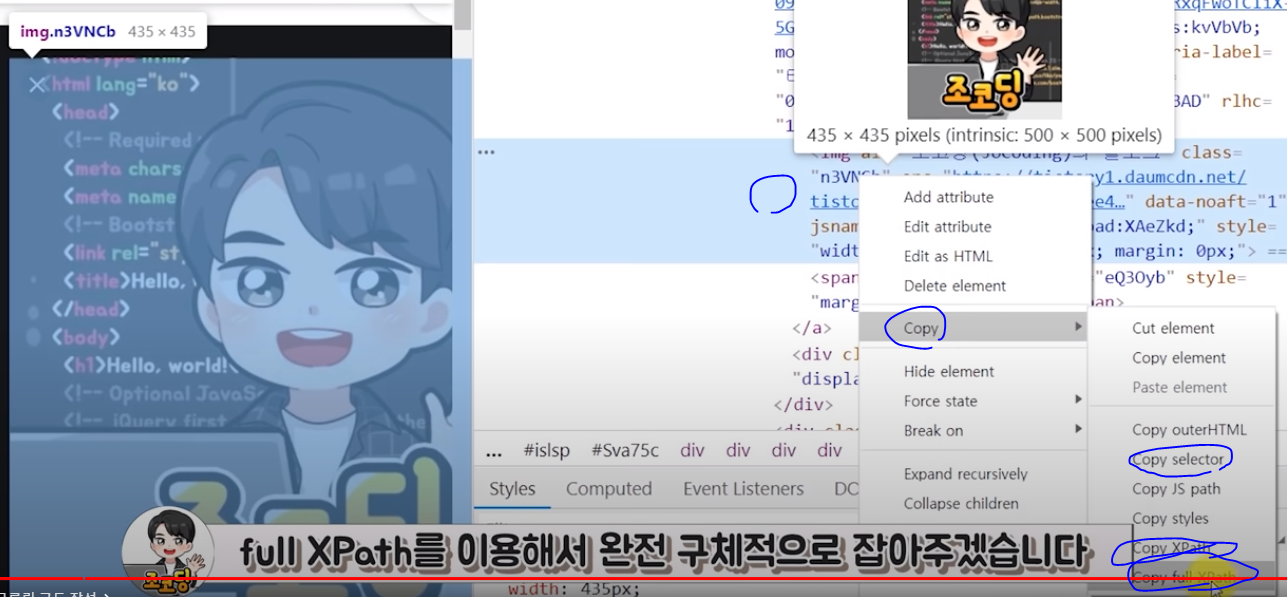
images = driver.find_elements_by_css_selector(".rg_i.Q4LuWd") count = 1 for image in images: image.click() time.sleep(3) imgUrl = driver.find_element_by_css_selector(".n3VNCb").get_attribute("src") urllib.request.urlretrieve(imgUrl, str(count)+".jpg") count += 1위의 코드를 fullXpath를 복사하고 by_xpath를 이용해 구체적으로 접근하도록 변경해주자
images = driver.find_elements_by_css_selector(".rg_i.Q4LuWd") count = 1 for image in images: try: image.click() time.sleep(2) imgUrl = driver.find_element_by_xpath('/html/body/div[2]/c-wiz/div[3]/div[2]/div[3]/div/div/div[3]/div[2]/c-wiz/div[1]/div[1]/div/div[2]/a/img').get_attribute("src") urllib.request.urlretrieve(imgUrl, str(count) + ".jpg") count = count + 1 except: pass
최종 코드
from selenium import webdriver from selenium.webdriver.common.keys import Keys import time import urllib.request driver = webdriver.Chrome() driver.get("https://www.google.co.kr/imghp?hl=ko&tab=wi&authuser=0&ogbl") elem = driver.find_element_by_name("q") elem.send_keys("조코딩") elem.send_keys(Keys.RETURN) SCROLL_PAUSE_TIME = 1 # Get scroll height last_height = driver.execute_script("return document.body.scrollHeight") while True: # Scroll down to bottom driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # Wait to load page time.sleep(SCROLL_PAUSE_TIME) # Calculate new scroll height and compare with last scroll height new_height = driver.execute_script("return document.body.scrollHeight") if new_height == last_height: try: driver.find_element_by_css_selector(".mye4qd").click() except: break last_height = new_height images = driver.find_elements_by_css_selector(".rg_i.Q4LuWd") count = 1 for image in images: try: image.click() time.sleep(2) imgUrl = driver.find_element_by_xpath('/html/body/div[2]/c-wiz/div[3]/div[2]/div[3]/div/div/div[3]/div[2]/c-wiz/div[1]/div[1]/div/div[2]/a/img').get_attribute("src") urllib.request.urlretrieve(imgUrl, str(count) + ".jpg") count = count + 1 except: pass driver.close()전체적인 코드의 흐름을 정리해보면 아래와 같다
1. 다운받은 크롬 웹드라이브를 지정
2. 크롬 웹드라이버를 이용해 구글 이미지 검색 주소로 들어가준다.
3. 검책창 착고
4. 조코딩을 입력하고
5. 엔터를 눌러준다.
6. 브라우저의 높이를 구해 저장하고 스크르롤을 내리면서 기다려주고
변화한 브라우저의 높이가 있다면 계속 반복하고 이전 브라우저의 높이와 새로운 브라우저의 높이가 같다면
스크롤이 끝까지 내려온 것이므로 결과 더보기 버튼이 있으면 클릭해서 계속 더 내리고
다시 한번 스크롤이 끝까지 내려가 결과더보기를 찾을 경우 에러가 나는데(이미 한번 클릭하고 내려갔기때문)
이때 except로 빠져 반복문을 빠져 나와 준다.
7. 검색했을때 나오는 작은 이미지들의 리스트를 images 변수에 할당한다.
8. 이렇게 작은 이미지들을 반복문으로 돌려 그 이미지들 중 하나씩 뽑아서 클릭하면 큰 이미지가 나오고
로딩되는것을 기다렸다가 큰 이미지의 주소 부분을 가져와 imgUrl 변수에 저장해준다.
9. 이미지를 다운로드받는 코드를 이용해 imgUrl을 계속 변하는 count를 이용해 중복을 피하며 이미지를 저장해준다.
10. 마지막으로 브라우저의 창을 닫아주면 된다.
2초마다 1장씩 이미지를 다운로드하며 총 700장 이상의 사진 전부를 가져온 것을 확인 할 수 있다.

selenium을 이용해 브라우저에 나올 수 있는 모든 정보에 대해서 크롤링이 가능하며 그 과정을 자동화 할 수 있다.
출처 : 조코딩 유투브
www.youtube.com/watch?v=1b7pXC1-IbE
728x90반응형'TIL' 카테고리의 다른 글
TIL.38 예외 발생시키기 및 만들기 (0) 2020.11.15 TIL.37 예외처리하기(try, except) (0) 2020.11.14 TIL.35 두점 사이의 거리 구하기 (0) 2020.11.12 TIL.34 클래스 상속(오버라이딩 및 추상클래스) (0) 2020.11.11 TIL.33 클래스 상속(기반 클래스 및 파생클래스) (0) 2020.11.10