-
TIL. 20 set_조작하기_2TIL 2020. 10. 28. 18:59728x90반응형
## 집합 연산 사용하기
## 합집합 (union)
## 합집합에서는 | 라는 기호를 사용하며 이 기호를 OR연산자라 부른다.
## 세트1 | 세트2 _구조 1
## set.union(세트1, 세트2) _구조 2
# 세트 1, 2를 더하세요
a = {1, 2, 3, 4}
b = {3, 4, 5, 6}
print(a | b)
print(set.union(a, b))
:: {1, 2, 3, 4, 5, 6}

{1, 2, 3, 4, 5, 6}
## 교집합(intersection)
## 교집합에서는 & 라는 기호를 사용하며 이 기호를 AND 연산자라 부른다.
## 세트1 & 세트2
## set.intersection(세트1, 세트2)
# 세트 1, 2 모두(중복) 들어있는 값을 구하세요
a = {1, 2, 3, 4}
b = {3, 4, 5, 6}
print(a & b)
print(set.intersection(a, b))
:: {3, 4}
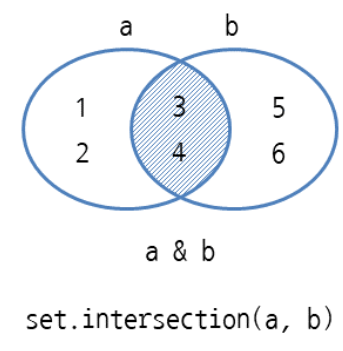
{3, 4}
## 차집합(difference)
## 차집합에서는 - 라는 기호를 사용하며 이 기호를 뺴기 연산자라 부른다.
## 세트1 - 세트2
## set.difference(세트1, 세트2)
# 세트 1 에서 세트 2에 있는 값을 빼세요.
a = {1, 2, 3, 4}
b = {3, 4, 5, 6}
print(a - b)
print(set.difference(a, b))
:: {1, 2}

{1, 2} print(b - a)
:: {5, 6}
## 대칭 차집합(symmertric_difference)
## 대칭 차집합에서는 ^ 라는 기호를 사용하며 XOR 연산자라 부른다 (BetaOR이라고도 부른다 )
## 세트1 ^ 세트2
## set.symmetric_difference(세트1, 세트2)
## 대칭차집합 def == 한 집합에는 포함할 수 있지만 두 집합 전부에는 포함되지 않는 원소들의 집합.
## a = {1, 2, 3, 4} // b = {3, 4, 5, 6}
## a - b = {1, 2} // b - a = {5, 6}
## a, b의 차집합들 간의 합집합이라고 생가하면 된다 (a-b)U(b-a) == (a-b) | (b-a)
a = {1, 2, 3, 4}
b = {3, 4, 5, 6}
print(a ^ b)
print(set.symmetric_difference(a, b))
:: {1, 2, 5, 6}

{1, 2, 5, 6}
## 집합 연산 사용 후 할당 연산자 사용하기
## set 자료형에 |, &, -, ^ 연산자와 =(할당연산자)를 함께 사용하면 집합 연산의 결과를 다시 변수에 할당한다.
## 집합 연산자와 할당연산자가 만나면 .update 메서드와 같은 역할을 수행한다.
## 합집합(union)
## 세트 1 과 세트 2를 더하고 재할당한다
## 세트1 |= 세트2
## 세트1.update(세트2)
a = {1, 2, 3, 4}
a |= {6}
print(a)
:: {1, 2, 3, 4, 6}
a.update({9}) ##union은 들어가지 않는다.
print(a)
:: {1, 2, 3, 4, 6, 9}
## 교집합(intersection)
## &= // 세트 1과 세트 2 의 겹치는 요소만으로 세트1에 재할당한다.
## 세트1 &= 세트2
## 세트1.intersection_update(세트2)
a = {1, 2, 3, 4}
a &= {0, 1, 3, 4, 5, 6}
print(a)
:: {1, 3, 4}
a.intersection_update({3, 4, 5})
print(a)
:: {3, 4}
## 차집합(difference)
## -= // 세트 1 에서 세트 2에 들어있는 값을 뺴고 세트1에 재할당한다.
## 세트1 -= 세트2
## 세트1.difference_update(세트2)
a = {1, 2, 3, 4, 5}
a -= {0, 4, 5, 6}
print(a)
:: {1, 2, 3}
a.difference_update({2, 4, 6})
print(a)
:: {1, 3}
## 대칭차집합(symmertric_difference)
## ^= // 세트 1와 세트 2에서 겹치지 않는 요소들로만 세트 1에 재할당한다.
## 세트1 ^= 세트2
## 세트1.symmetric_difference_update(세트2)
a = {1, 2, 3, 4, 5}
a ^= {0, 2, 4, 6, 8}
print(a)
:: {0, 1, 3, 5, 6, 8}
a.symmetric_difference_update({1, 3, 5, 7})
print(a)
:: {0, 6, 7, 8}
## 부분집합과 상위집합 확인하기
# set는 부분집합, 진부분집합, 상위집합, 진상위집합과 같이 속하는 관계를 표현할 수 있다.
# 부등호 , 등호를 사용하여 표기 할 수 있다 (< , > , =)
# a가 b의 부분집합인지 / b가 a의 상위집합인지 속하는 관계를 확인하는 법으로 수학적으로 접근하면 이해하기 쉽다.
## 부분집합
## 현제세트가 다른 세트의 부분집합인지 확인하는 방법 및 메서드
## 현재세트 <= 다른세트
## 현재세트.issubset(다른세트)
## <= 와 .issubset() 동일하게 생각하자 // is_sub_set 연결해서 issubset
a = {1, 2, 3, 4}
print(a <= {1, 2, 3, 4})
print(a.issubset({1, 2, 3, 4}))
:: True
print(a <= {1, 2, 3, 4, 5})
:: True
print(a <= {1, 2, 3})
::False

## 진부분집합
## 현제세트가 다른 세트의 진부분집합인지 확인하는 방법, 별도 메서드 없음
## 현재세트 < 다른세트
## 진부분집합은 부분집합에서 자신과 동일한 것을 제외한 것을 진부분집합으로 이해 할 수 있다.
a = {1, 2, 3, 4}
print(a < {1, 2, 3, 4})
:: False ## 자신과 동일한 것은 진부분집합 관계가 아님
print(a < {1, 2, 3, 4, 5})
:: True
print(a < {1, 2, 3})
:: False

## 상위집합
## 현제세트가 다른 세트의 상위집합인지 확인하는 방법 및 메서드
## 현재세트 >= 다른세트
## 현재세트.issuperset(다른세트)
## >= 와 .issuperset() 동일하게 생각하자 // is_super_set 연결해서 issuperset
a = {1, 2, 3, 4}
print(a >= {1, 2, 3, 4})
print(a.issuperset({1, 2, 3, 4}))
:: True
print(a >= {1, 2, 3, 4, 5})
:: False
print(a >= {1, 2, 3})
:: True

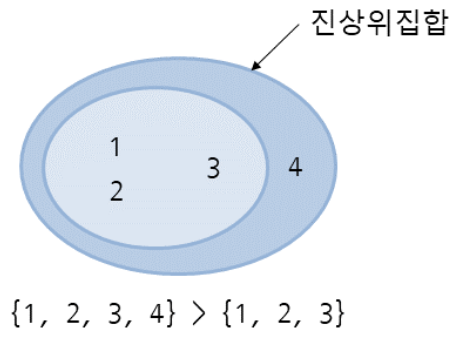
## 진상위집합
## 현제세트가 다른 세트의 진상위집합인지 확인하는 방법, 별도 메서드 없음
## 현재세트 >= 다른세트
a = {1, 2, 3, 4}
print(a > {1, 2, 3, 4})
:: False
print(a > {1, 2, 3, 4, 5})
:: False
print(a > {1, 2, 3})
:: True
## set가 같은지 다른지 확인하기
## == 연산자를 이용해 확인 가능하다.
a = {1, 2, 3, 4}
print(a == {1, 2, 3, 4})
:: True
print(a == {3, 1, 2, 4})
:: True
## 요소의 순서가 없으므로 요소만 같다면 True
## != 연산자 이용 확인 가능
a = {1, 2, 3, 4}
print(a != {1, 2, 3, 4})
:: False ## 아니요 a는 {세트}와 다르지 않습니다 (같습니다)
print(a != {1, 2, 4})
:: True ## 네 a 는 {세트}와 다릅니다 (같지 않다)
## set가 겹치는지 확인하기
## 현제 세트와 다른세트가 "겹치지 않는지"를 확인한다. // 겹치지 않으면 True
## 현재세트.isdisjoint(다른세트)
a = {1, 2, 3, 4}
print(a.isdisjoint({1, 5, 6, 4}))
:: False ## 1, 4가 겹침
print(a.isdisjoint({5, 6, 7}))
# True ## 겹치지 않
## set 조작하기
# add
# 세트에 요소 추가
a = {1, 2, 3}
a.add(5)
print(a)
:: {1, 2, 3, 5}
# remove
# 세트에서 특정 요소값을 삭제
a = {1, 2, 3, 4}
a.remove(3)
print(a)
:: {1, 2, 4}
## discard
# 세트에서 특정 요소값을 삭제
a = {1, 2, 3, 4}
a.discard(3)
print(a)
:: {1, 2, 4}
## a.remove(3) ## set안에 3이라는 요소가 없는 상태이므로 error 발생
a.discard(3) ## set 안에 3이라는 요소가 없지만, error가 발생하지 않고 넘어감! _remove와 차이점
print(a)
:: {1, 2, 4}
# pop
# 세트에서 임의의 요소를 삭제함
b = {1, 2, 3, 4}
b.pop() # 1, 2, 3, 4 를 랜덤하게 삭제해야하는데 계속 맨 앞의 인덱스가 지워짐(숫자로만 이루어져있어 그런듯하다)

# clear
# 세트의 모든 요소 삭제
a = {1, 2, 3, 4}
a.clear()
print(a) # 다 삭제하면 빈 세트만 남음
:: set()
# len
# 세트의 길이를 구함
a = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 10}
print(len(a))
:: 10 ## 10 이 중복되어있어 하나만 적용
## set 의 할당과 복사
## set 에서의 할당과 복사는 list와 동일하다 (2차원 list는 deepcopy 사용해야함)
## 할당
a = {1, 2, 3, 4}
b = a
b.add(5)
print(a)
print(b)
:: {1, 2, 3, 4, 5}
## 세트 1개 변수 2개로 세트 1개를 부르는 이름만 다를뿐이다.
## 하나의 변수를 변경시 다른 변수도 동일하게 적용
## 복사
# .copy
a = {1, 2, 3, 4}
b = a.copy()
b.add(5)
print(a)
:: {1, 2, 3, 4}
print(b)
:: {1, 2, 3, 4, 5}
## 세트 2개 변수 2개
## 하나의 변수를 변경시 다른 변수는 영향을 받지 않음
## 반복문을 이용한 set 요소 출력하기
a = {1, 2, 3, 4, 5}
b = {'k', 'o', 'r', 'e', 'a'}
for i in a:
print(i, end=' ')
for i in b:
print(i , end=" ")
for i in {1, 2, 3, 4, 5}:
print(i)
## 반복문을 이용해 세트 요소를 출력할 수 있으며
## 원래 세트는 요소의 순서가 정해져있지 않지만, 숫자로만 구성되어 있다면 순서대로 출력이된다
## 위의 코드에서 숫자와 문자열의 경우 숫자는 1 2 3 4 5 가 일정하게 출력되고 문자열은 랜덤하게 출력된다.
## set 표현식 사용하기
## {식 for 변수 in 반복가능한객체} _ 추천
## set(식 for 변수 in 반복가능한객체)
a = {i for i in 'apple'}
print(a)
:: {'p', 'l', 'e', 'a'}
## 여기서 a p p l e를 꺼내오고 출력을하며 여기서 유일한문자(중복없는) a p l e 가 요소의 순서 없이 랜덤하게 출력된다.

## {식 for 변수 in 세트 if 조건식} _ 추천
## set(식 for 변수 in 세트 if 조건식)
a = {i for i in 'pineapple' if i not in 'apl'}
print(a)
:: {'n', 'e', 'i'}
## 먼저 'pineapple'에서 유일한 문자만을 뽑은뒤 if 조건문으로 검증한다.
## if i not in 'apl' 이란 뜻은 뽑아온 'pineapple'을 i에 라는 변수에 일일이 담아 i가 a p l 인지 아닌지 검증하고
## 아닌 경우에만 뽑아 사용하라는 의미이다.

c = {i for i in range(10) if i != 2 and i != 7}
print(c)
:: {0, 1, 3, 4, 5, 6, 8, 9}
## if i != 2 and i != 7 // 0 ~9 중 i 가 2가 아니고 , 7이 아닐경우 값을 넘겨줘라 라는 의미.
 728x90반응형
728x90반응형'TIL' 카테고리의 다른 글
TIL. 22 회문 판별하기 (0) 2020.10.30 TIL. 21 파일 사용하기 (0) 2020.10.29 TIL.19 set 조작하기 (0) 2020.10.27 TIL. 18 Dictionary 조작하기 (0) 2020.10.26 TIL. 17 python 과제 (목차확인) (0) 2020.10.25